A well-designed ethernet ring topology gives a plant a second path without forcing a full mesh of switches. That matters in manufacturing, utilities, warehouses, and camera networks where one broken cable should not stop control traffic. In this article I break down how the ring works, why unmanaged loops fail, which protection methods are worth using, and what I would check before commissioning one.
The main thing to remember about ring-based Ethernet
- A ring adds resilience by giving traffic an alternate path when a link fails.
- Unmanaged loops are dangerous because Ethernet frames can circulate indefinitely.
- Industrial rings usually rely on a specific protection method such as DLR, MRP, REP, or G.8032.
- Fast recovery is possible, but the real timing depends on the protocol, switch family, and ring size.
- The best designs are small, documented, and tested under real traffic, not just on a bench.
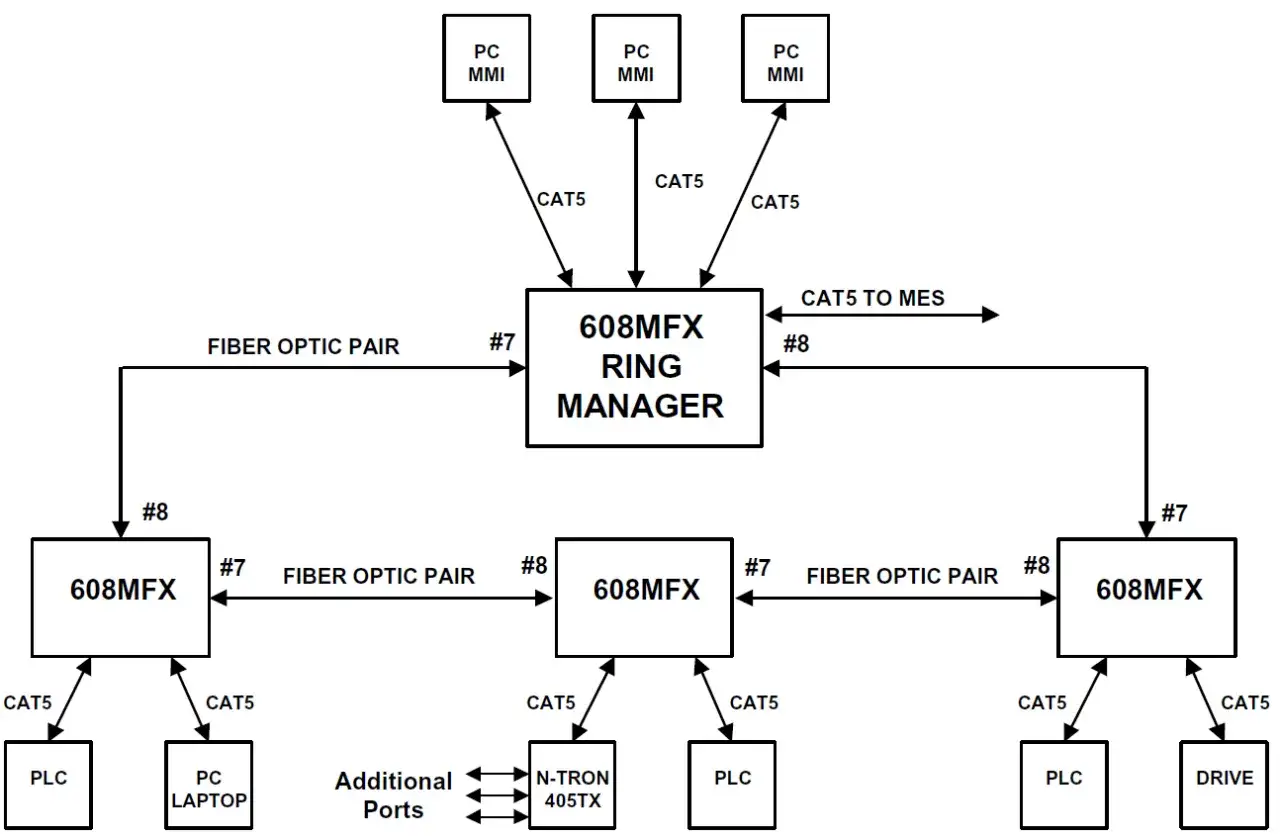
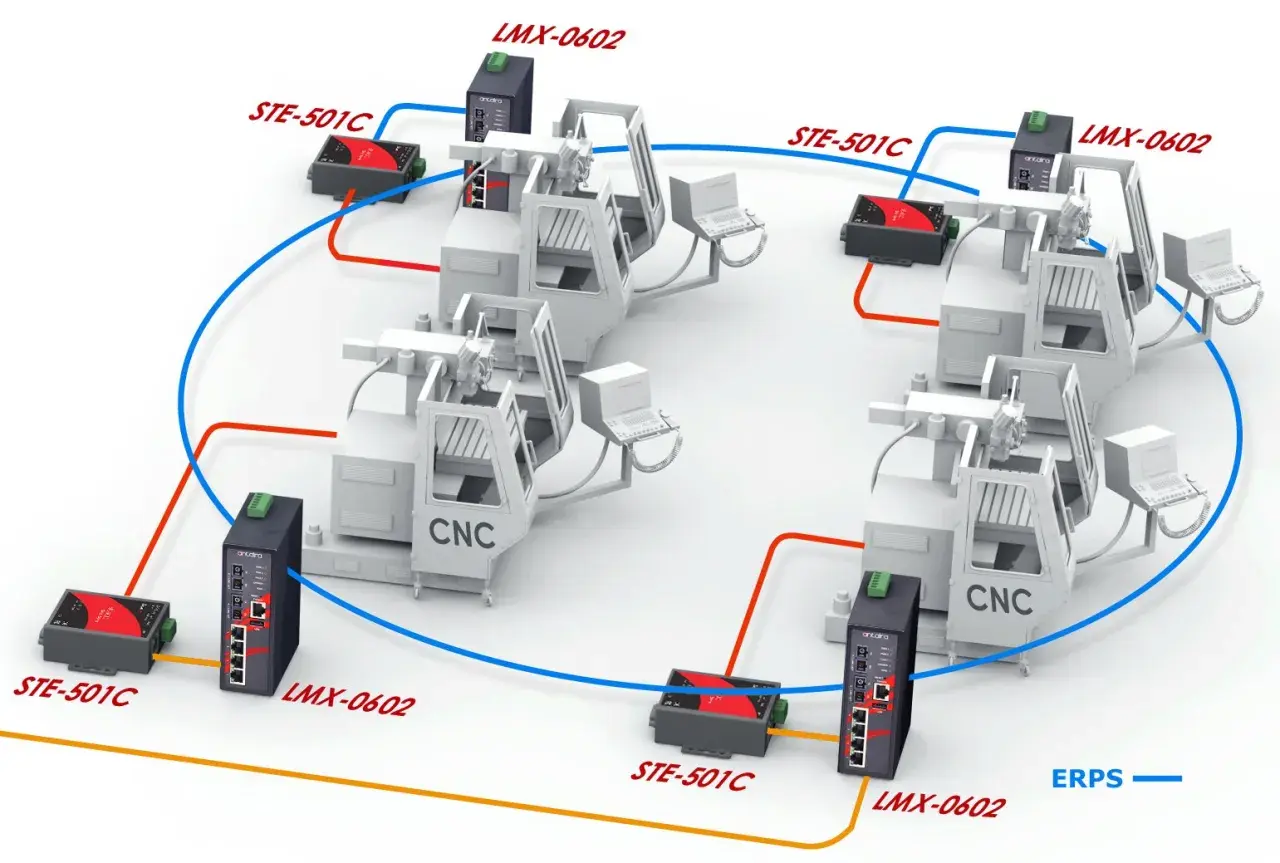
How a ring keeps industrial traffic moving
I picture a ring as a line that has been closed back on itself. Each switch or device normally has two neighbours, and the control protocol keeps the loop safe by letting traffic use one active path while leaving the other path ready for a failure. In a warehouse perimeter, a conveyor line, or a camera ring around a production hall, that gives you a second route without paying for a fully meshed design.
- Normal state one leg of the ring is effectively reserved so frames do not circulate endlessly.
- Failure state the blocked or standby path is opened and traffic reroutes around the break.
- Recovery state the network settles back into its protected pattern once the fault is cleared.
The benefit is simple: one broken cable should not take down every downstream device. That efficiency is useful, but only if the loop is controlled, which is where the trouble starts.
Why unmanaged loops fail fast
Plain Ethernet does not like uncontrolled loops. When frames keep circulating, the network can flood itself with broadcasts, duplicate packets, and MAC table churn. The symptoms are usually obvious: response times jump, switches start relearning the same addresses on different ports, and devices appear to behave erratically even though the cabling looks fine.
- Broadcast storms consume bandwidth and make even healthy links look broken.
- MAC flapping confuses switches because the same address appears on multiple ports.
- Duplicate control traffic can upset PLCs, HMIs, and time-sensitive devices.
Generic tools such as STP and RSTP can stop loops in mixed-purpose networks, but in industrial settings I usually want something that is designed for the ring rather than merely tolerant of it. Once you understand the failure mode, the next question is which protection protocol fits the job.
Which protection method fits the job
The right choice depends on the hardware you already have and how quickly you need traffic back after a fault. In modern industrial networks, the usual contenders are ring-specific protocols rather than a single generic approach. I treat the recovery time as a design target, not a promise, because real behaviour still depends on firmware, traffic load, and ring size.| Protocol | Typical use | What it gives you | Main trade-off |
|---|---|---|---|
| DLR | EtherNet/IP device-level rings | Very fast recovery, often cited at around 3 ms in a 50-node ring | Needs compatible devices and a ring supervisor |
| MRP | PROFINET cells and plant-floor rings | Simple media redundancy with typical reconfiguration around 200 ms in medium rings | Slower than the fastest device-level options |
| G.8032 / ERPS | Carrier-style or backbone rings | Standards-based ring protection with strong loop prevention | Exact timing depends heavily on the switch platform |
| REP | Cisco-centric industrial Ethernet | Fast ring convergence inside a vendor ecosystem | Less useful if your environment is mixed-vendor |
| STP / RSTP | Generic or lower-criticality segments | Basic loop avoidance across broad switch mixes | Usually slower and less deterministic for control traffic |
If the ring sits inside a single automation ecosystem, I would start with that ecosystem’s preferred method. If you are mixing vendors, check compatibility before you buy anything. Choosing the protocol is only half the job; the other half is designing the ring so it behaves under pressure.
How I would design and commission one in a plant
When I design one of these networks, I start with the boring details because they are usually what fail in the field. A ring that looks elegant on paper can become fragile if you ignore cable length, firmware consistency, or which device is acting as the supervisor. In the UK, where older plant and new equipment often coexist, that discipline matters even more.
- Define the ring boundary Keep the ring where resilience actually matters, usually at the machine or cell edge.
- Confirm protocol support Every switch and endpoint on the ring must support the same redundancy method.
- Choose the supervisor role One device should control or monitor the ring, and that choice should be documented.
- Match the physical layer Use the same speed, duplex, optic type, and cabling standard throughout the ring.
- Prefer fibre where the environment is harsh Long runs, heavy machinery, and noisy electrical areas are usually easier to manage with fibre.
- Test failure under load Pull a cable and remove a switch while the network is busy, not when it is idle.
I also pay attention to maintenance. If someone has to bypass the ring for service, the procedure should be clear, repeatable, and short. A ring that takes five different workarounds to troubleshoot is not resilient, it is merely complicated. After that, the real decision is not just how to build a ring, but whether a ring is the right topology at all.
Where a ring wins and where it does not
Rings are useful, but they are not automatically the best answer. I usually reach for them when devices sit in a physical line, when the environment is harsh, and when I need a backup path without paying for a fully meshed design. For some parts of a plant, though, a star or redundant star is simpler and easier to live with.
| Topology | Best for | Why I choose it | Weak point |
|---|---|---|---|
| Ring | Long linear assets, perimeter cameras, machine skids | One alternate path with moderate cabling | Needs protocol support and careful commissioning |
| Star / tree | Cabinets and local cells with many nearby devices | Simple to manage and easy to troubleshoot | A central switch can become a single point of failure |
| Mesh | Critical backbones and highly available cores | Multiple alternate paths | More cost, more cables, more complexity |
In practice, I often use a hybrid design: rings at the machine edge, star or tree segments inside the cabinet, and a separate resilient backbone where traffic is heavier. That mix usually gives a better balance of cost, resilience, and troubleshooting time than forcing every part of the plant into the same shape. Before I sign off a design, I run through a short set of checks that catches most preventable failures.
What I would verify before go-live
Here is the checklist I trust before commissioning:
- Every switch and endpoint on the ring supports the chosen protocol.
- The supervisor or manager role is documented and easy to identify.
- Failover has been tested with real traffic, not just in an idle lab.
- Firmware, optics, and cabling standards are consistent across the ring.
- Maintenance staff know exactly how to isolate, repair, and restore the loop.
- Spare parts are available for the switch model that matters most.
If those boxes are ticked, a ring is usually a practical way to buy resilience without turning the plant network into a science project. If they are not, I would simplify the design first and add redundancy only where it clearly pays for itself.